Python pandas读写excel文件
read_excel()
read_excel(io,
sheetname=0,
header=0,
skiprows=None,
skip_footer=0,
index_col=None,
names=None,
parse_cols=None,
parse_dates=False,
date_parser=None,
na_values=None,
thousands=None,
convert_float=True,
has_index_names=None,
converters=None,
dtype=None,
true_values=None,
false_values=None,
engine=None,
squeeze=False,
**kwds
)
常用参数解析:
io: string, path object ; excel 路径。sheetname: string, int, mixed list of strings/ints, or None, default 0 返回多表使用sheetname=[0,1],若sheetname=None是返回全表 注意:int/string 返回的是dataframe,而none和list返回的是dict of dataframeheader: int, list of ints, default 0 指定列名行,默认0,即取第一行,数据为列名行以下的数据 若数据不含列名,则设定 header = Noneskiprows: list-like,Rows to skip at the beginning,省略指定行数的数据skip_footer: int,default 0, 省略从尾部数的int行数据index_col: int, list of ints, default None指定列为索引列,也可以使用u”strings”,读取的时候指定 索引names: array-like, default None, 指定列的名字。na_values:指定原数据集中哪些特征的值作为缺失值。na_filter: boolean, default True;是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。thousands:指定原始数据中的千位符comment:指定注释符,在读取数据时,如果碰到首行指定的注释符,则跳过该行。parse_datas:指明日期列,为字符串构成的 list; 数据源:
数据源:
sheet1:
ID NUM-1 NUM-2 NUM-3
36901 142 168 661
36902 78 521 602
36903 144 600 521
36904 95 457 468
36905 69 596 695
sheet2:
ID NUM-1 NUM-2 NUM-3
36906 190 527 691
36907 101 403 470
basestation ="F://pythonBook_PyPDAM/data/test.xls"
data = pd.read_excel(basestation)
print data
输出:是一个dataframe
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
sheet_name参数
:返回多表使用sheetname=[0,1],若sheetname=None是返回全表 注意:int/string 返回的是dataframe,而none和list返回的是dict of dataframe
data_1 = pd.read_excel(basestation,sheet_name=[0,1])
print(data_1)
print(type(data_1))
'''
OrderedDict([(0, ID NUN-1 NUM-2 NUM-3
0 36901 45 78 95
1 36902 47 45 63
2 39603 85 47 21
3 39604 96 36 45
4 39605 25 89 15),
(1, ID NUN-1 NUM-2 NUM-3
0 36906 58 52 47
1 36907 66 26 14)])
<class 'collections.OrderedDict'>
header参数
指定列名行,默认0,即取第一行,数据为列名行以下的数据 若数据不含列名,则设定 header = None ,注意这里还有列名的一行。
data = pd.read_excel(basestation,header=None)
print(data)
'''
0 1 2 3
0 ID NUN-1 NUM-2 NUM-3
1 36901 45 78 95
2 36902 47 45 63
3 39603 85 47 21
4 39604 96 36 45
5 39605 25 89 15
'''
data = pd.read_excel(basestation,header=[3])
print(data)
'''
39603 85 47 21
0 39604 96 36 45
1 39605 25 89 15
'''
skiprows参数
省略指定行数的数据
data = pd.read_excel(basestation,skiprows = [1])
print(data)
'''
ID NUN-1 NUM-2 NUM-3
0 36902 47 45 63
1 39603 85 47 21
2 39604 96 36 45
3 39605 25 89 15
'''
skip_footer参数
省略从尾部数的int行的数据
data = pd.read_excel(basestation, skip_footer=3)
print(data)
'''
ID NUN-1 NUM-2 NUM-3
0 36901 45 78 95
1 36902 47 45 63
'''
index_col参数
指定列为索引列,也可以使用u”strings”
data = pd.read_excel(basestation, index_col="NUM-3")
print(data)
'''
ID NUN-1 NUM-2
NUM-3
95 36901 45 78
63 36902 47 45
21 39603 85 47
45 39604 96 36
15 39605 25 89
'''
names参数
指定列的名字。
data = pd.read_excel(basestation,names=["a","b","c","e"])
print(data)
'''
a b c e
0 36901 45 78 95
1 36902 47 45 63
2 39603 85 47 21
3 39604 96 36 45
4 39605 25 89 15
'''
nrows参数
读取指定的几行数据
data = pd.read_excel(basestation, nrows=3)
print(data)
'''
ID NUN-1 NUM-2 NUM-3
0 36901 45 78 95
1 36902 47 45 63
2 39603 85 47 21
'''
usecols 参数
读取指定的列, 也可以通过名字或索引值(指定需要读取原数据集中的哪些变量名,以列表传入。)
data = pd.read_excel(basestation, usecols=2)
print(data)
'''
ID NUN-1 NUM-2
0 36901 45 78
1 36902 47 45
2 39603 85 47
3 39604 96 36
4 39605 25 89
'''
to_excel()
存储函数为pd.DataFrame.to_excel(),注意,必须是DataFrame写入excel, 即Write DataFrame to an excel sheet。其具体参数如下:
to_excel(self,
excel_writer,
sheet_name='Sheet1',
na_rep='',
float_format=None,
columns=None,
header=True,
index=True,
index_label=None,
startrow=0,
startcol=0,
engine=None,
merge_cells=True,
encoding=None,
inf_rep='inf',
verbose=True,
freeze_panes=None
)
数据源:
ID NUM-1 NUM-2 NUM-3
0 36901 142 168 661
1 36902 78 521 602
2 36903 144 600 521
3 36904 95 457 468
4 36905 69 596 695
5 36906 165 453
加载数据:
basestation ="./ex.xls"
basestation_end ="./test_end.xls"
data = pd.read_excel(basestation)
参数excel_writer
输出路径
data.to_excel(basestation_end)
sheet_name
将数据存储在excel的那个sheet页面
data.to_excel(basestation_end,sheet_name="sheet2")
na_rep
缺失值填充
data.to_excel(basestation_end,na_rep="NULL")
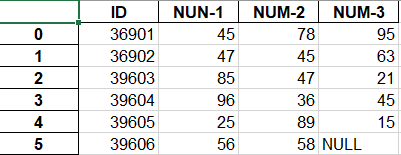
colums
sequence, optional,Columns to write 选择输出的的列。
data.to_excel(basestation_end,columns=["ID"])
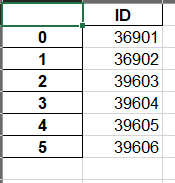
header
boolean or list of string,默认为True,可以用list命名列的名字。header = False 则不输出题头。
data.to_excel(basestation_end,header=["a","b","c","d"])
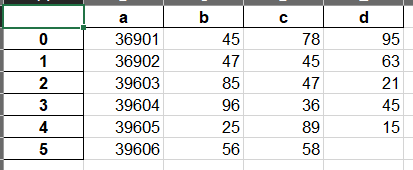
header = False 则不输出题头
data.to_excel(basestation_end,header=False,columns=["ID"])
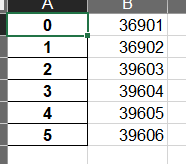
index
boolean, default True Write row names (index) 默认为True,显示index,当index=False 则不显示行索引(名字)。 index_label : string or sequence, default None 设置索引列的列名。
data.to_excel(basestation_end,index=False)
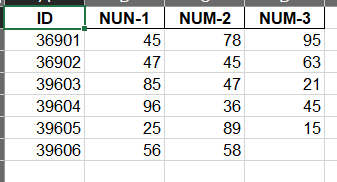
index_label
设置索引列的列名
data.to_excel(basestation_end,index_label=["f"])
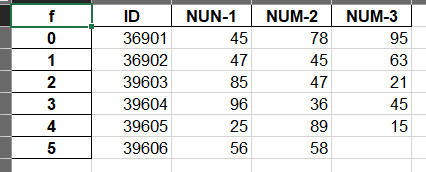
案例
写入excel,自定义索引
data={'ID':[1,2,3,4],
'year':[2000,2001,2002,2003],
'pop':[3.7,3.6,2.4,0.9]}
df=pd.DataFrame(data)
print(df)
'''
ID year pop
0 1 2000 3.7
1 2 2001 3.6
2 3 2002 2.4
3 4 2003 0.9
'''
df.to_excel('text.xls')

data={'ID':[1,2,3,4],
'year':[2000,2001,2002,2003],
'pop':[3.7,3.6,2.4,0.9]}
df=pd.DataFrame(data)
df=df.set_index('ID')
df.to_excel('text.xls')

读取的数据无表头,为其添加新的表头并保存

people=pd.read_excel('People.xlsx',header=None)
people.columns=['id', 'type', 'title', 'First', 'Middle', 'Last']
print(people.columns)
#Index(['id', 'type', 'title', 'First', 'Middle', 'Last'], dtype='object')
#默认添加行索引 ,可以重新指定
people=people.set_index('id')
people.to_excel('people2.xls')
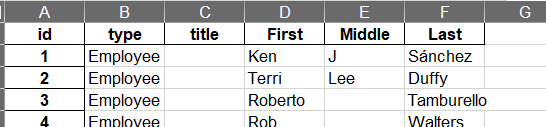
指定列为索引,避免自动pands再生成新的索引
#指定某列为索引 ,pands就不会再自动生成索引
people=pd.read_excel('people2.xls',index_col='id')
将多个Sheet写入到本地同一Excel文件中
import pandas as pd
#读取两个表格
data1=pd.read_excel('文件路径')
data2=pd.read_excel('文件路径')
#将两个表格输出到一个excel文件里面
writer=pd.ExcelWriter('D:新表.xlsx')
data1.to_excel(writer,sheet_name='sheet1')
data2.to_excel(writer,sheet_name='sheet2')
#必须运行writer.save(),不然不能输出到本地
writer.save()

with pd.ExcelWriter(r'C:\Users\数据\Desktop\data\test2.xls') as writer:
df1.to_excel(writer, sheet_name='df1')
df2.to_excel(writer, sheet_name='df2')
将多个 sheet 写入到一个文件的时候,切记 close 文件